Kubernetes and Reconciliation Patterns

Kubernetes is one of the most successful open source projects, and the most popular one in the cloud infrastructure space. Initially released in 2014, it has gone through a meteoric rise to become the de-facto standard container orchestration engine. I still vividly remember the days when we wanted to architect a brand new application to deploy in a public cloud back in 2017, and we were debating how to choose between Kubernetes, Mesos, and Docker Swarm. We ended up choosing Kubernetes, but as part of our analysis, we even evaluated the cost of a potential migration away from Kubernetes, should it not really become mainstream. Fast forward to today, and Kubernetes is not only the orchestrator of choice for containerized workloads, it has also become the de-facto standard API layer for software-defined infrastructure.
To understand how it evolved from a container orchestrator to a more general-purpose automation engine, it is important to look into the role that two fundamental enablers played:
- Reconciliation (controller) Loops
- Custom Resources
A Reconciliation loop, also referred to as a control loop, is a loop that basically runs forever, and at each run, reconciles the actual state of the system with the desired state. To achieve that, the controller needs to constantly observe the current state and make sure that it matches the desired state. If the controller detects a mismatch, it needs to reconcile the two states; hence the reconciliation loop.
In the beginning, Kubernetes had a number of native resources and few built-in control loops for stateless and stateful applications. It soon became clear that the built-in support for stateful workloads via StatefulSets was not enough. In addition, it was not easy to innovate by adding new resource types and control loops on top of the control plane. A major addition in 2017 paved the way for a powerful way to extend the core APIs by adding support for custom resources and custom controllers. If you are like me and are curious about the history and context of significant architecture decisions and the thought process behind them, I think this post does a great job explaining the idea from those early days. You will even see that the idea of custom resources was a successor and refined version of an earlier iteration, called Third Party Resources (TPRs)1.
As these additions gradually matured, they enabled a lot of innovation to happen in the space of automation in cloud native infrastructure. In this post, I’ll dive a bit deeper into the concept of reconciliation followed by the main automation patterns that have emerged over the past few years and how they make it possible to use the core Kubernetes API server combined with add-ons and extensions to automate the lifecycle of various layers of software-defined infrastructure.
Custom Resources and Custom Controllers
Kubernetes official documentation defines a custom resource to be a Kubernetes API endpoint that stores a collection of API objects of a certain kind. In practice, when you model a thing as a custom resource, you bring it into the Kubernetes domain. This enables leveraging important features offered by the API server such as authentication and authorization, persistence of its state, CRUD operations on the instances of the resource, etc. For instance, you can model a cloud load balancer, a database server, a git source code repository, or any other type of infrastructure resource as a custom resource2.
Creating a custom resource is not the whole story though. The other important (and arguably much more complex) task is to write a custom controller associated with the custom resource. The custom controller is a piece of software that encapsulates all the knowledge required to reconcile the actual state of the resource with its desired state. And it is the combination of the two that creates a truly declarative API style.
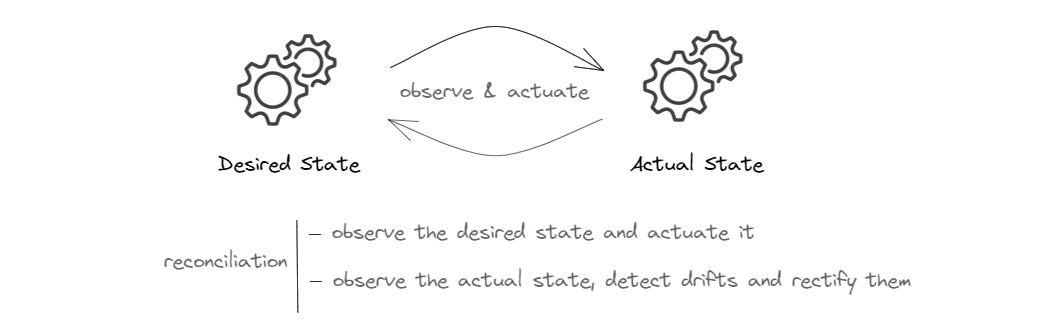
Reconciliation has a bidirectional nature. It involves observing both the desired state and the actual state. Sometimes, the desired state is updated to reflect a new intent. In such cases, the control loop implementing the reconciliation logic must do what it takes to update the actual state of the resource so that it matches the new intent. And of course the world is not perfect as we know; things break and the actual state may drift and no longer match the desired state. When the controller detects a drift, it must do what it takes to restore it to the desired state.
In the remainder of this post, I’ll present the three dominant patterns that capture the crux of the Kubernetes-driven automation that has emerged since the inception of custom resources and custom controllers. Each pattern is complemented with several examples to better illustrate the points.
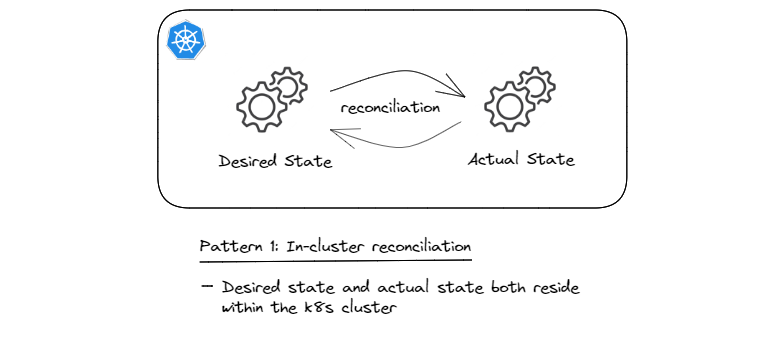
Pattern 1: In-cluster Reconciliation
This is the starting pattern, initially established as part of providing the built-in resources and controllers. What CRDs and custom controllers enable is extending these built-in control loops in order to model and automate the lifecycle of other types of resources, all while leveraging the API server and it capabilities such as REST API style, access control, object persistence, etc.
Basically, in this pattern the desired state (source of truth) resides in the API server3 and the associated custom controller(s) ensure that the system resources are created within the cluster and kept up-to-date to always fulfill the declared desired state.
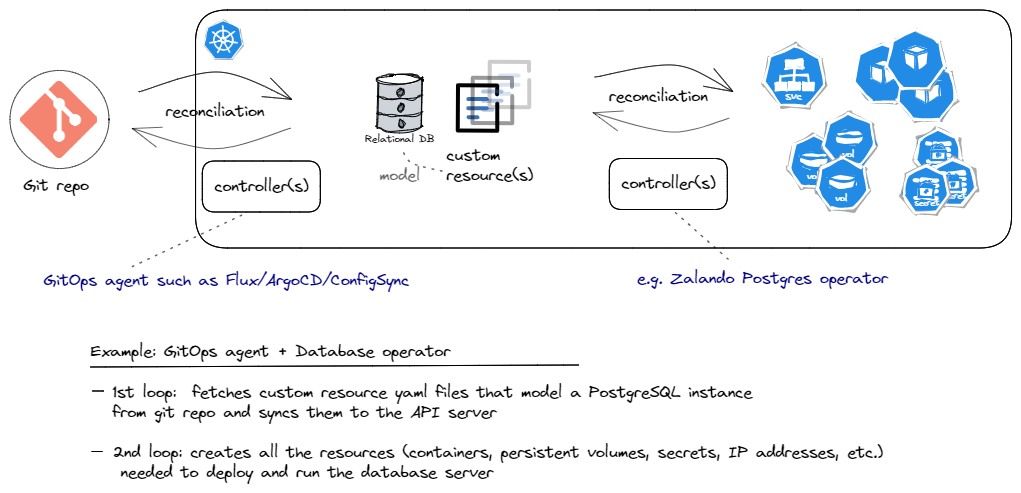
As an example, imagine we’d like to run a popular relational database server such as PostgreSQL in our Kubernetes cluster. As stated before, the built-in resources and controllers cannot really address the complexities inherent in deploying and running a database server. But a seasoned DBA team can model the database server using CRDs and then build the custom controllers that encapsulate all the knowledge required to automate the handling of the database server’s lifecycle. Tasks such as deploying a highly available database server, upgrading the software or schemas, adding more replicas, creating backups, etc. are examples of the operational knowledge that can be encoded into the custom controllers. That’s why the use of custom resources and controllers to manage stateful applications such as a database server is also referred to as the operator pattern.
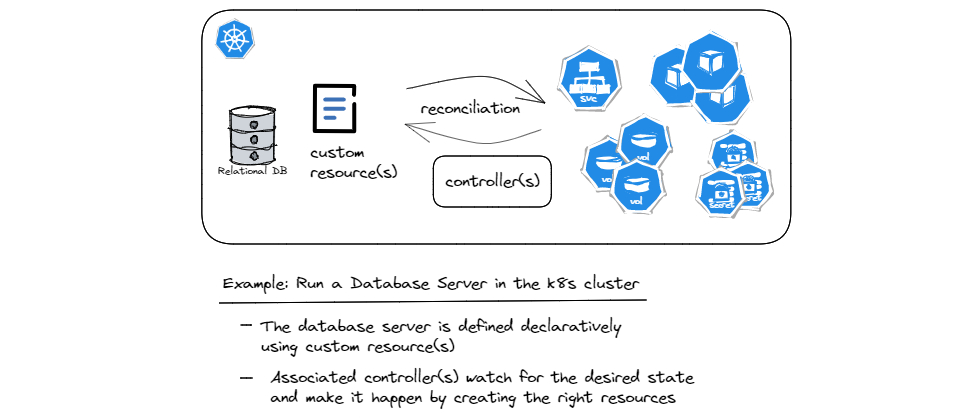
As you can see in the diagram, the custom resource(s) define what the database server should look like, e.g. in terms of the software version, number of replicas, storage size, the endpoint where the service can be reached, etc. Additionally, custom resources may allow configuring policies such as the range within which software upgrades/patches can happen automatically, when backups are created, how long they are kept before being cleaned up, etc. These attributes collectively describe the desired state of the database server. Now what the controllers do in response, is that as part of the continuous reconciliation loops, they ensure that the right number of Pods running the right software version, persistent volumes with the right size, and other prerequisites such as credentials, networking, etc. are all handled automatically.
This pattern shows how Kubernetes can enable higher degrees of automation in operating software infrastructure components. Indeed, the sheer number of Kubernetes operators published by open source communities as well as commercial vendors found in operatorhub.io is a testament to the success and wide adoption of this pattern (as well as other patterns that I’ll discuss in the remainder of this post).
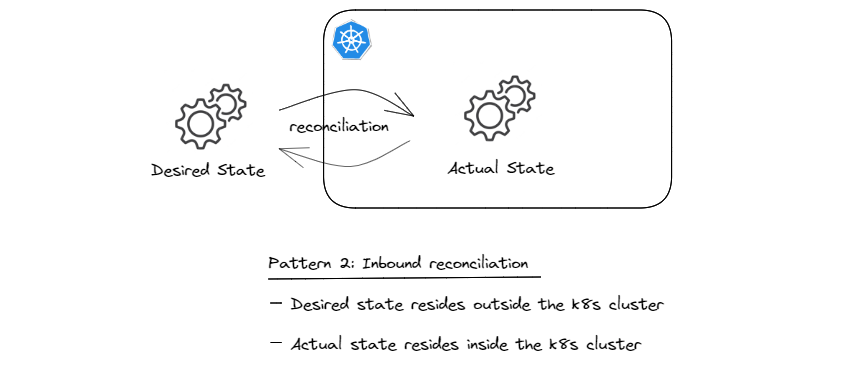
Pattern 2: Inbound Reconciliation
In-cluster reconciliation (pattern 1) relies on the assumption that the desired state resides in the API server (technically in the persistence layer; e.g. etcd). This pattern does not care where the configuration originally comes from. One of the possibilities is that the desired state, which is typically some sort of configuration, is pushed to the Kubernetes cluster; e.g. using kubectl, helm, or similar API clients. The problem with this imperative approach is the fire and forget nature of configuration management and the fact that there is no drift detection and continuous reconciliation. And at any given moment, there is no reliable way of knowing what the desired state of the system is, other than looking at the current state in the API server.
A different approach is to extend the declarative nature of pattern 1 to the configuration which originally comes from outside the cluster. Following this approach, which I refer to as inbound reconciliation, we treat the source of configuration outside the cluster as the desired state and what gets stored in the API server as the actual state. The reconciliation performed in this context is about making sure that what gets stored in the API server is always in sync with the source of truth that resides outside the cluster, as shown in the sketch below.
This pattern was popularized by GitOps as a modern way of operating cloud native (read Kubernetes native) applications. The pattern reuses two fundamental principles that Kubernetes promotes (declarative state and continuous reconciliation) and adds two additional principles: (1) An external versioned and immutable source of truth and (2) automatically pulling updates into the cluster.
Since Git has become the de-facto standard for source code version control systems, the focus was initially on Git (and hence the name GitOps), but many GitOps agents have also added support for OCI compliant registries for fetching artifacts. Examples of these registries are GitHub Container Registry, GitLab Container Registry, and similar registries provided by hyperscale cloud providers.
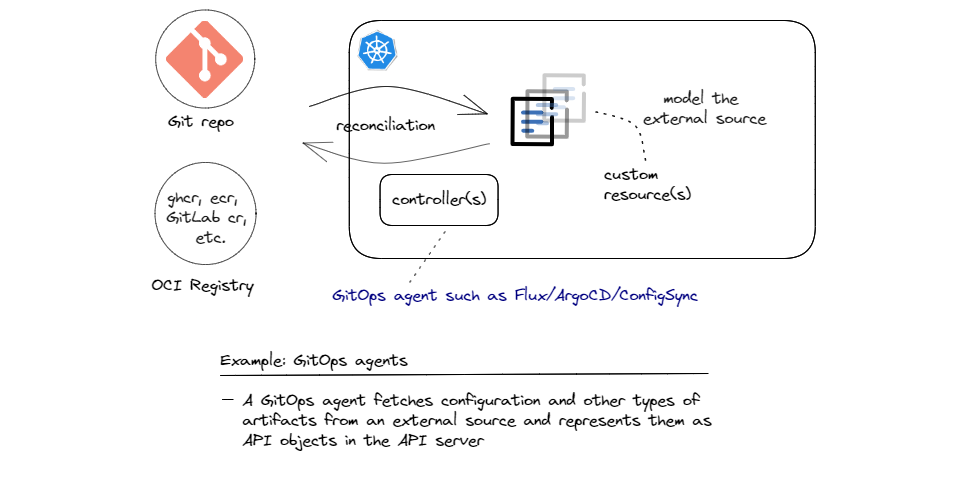
The implementation of this architecture pattern can be done in various ways. For instance, Flux has a very nice and modular architecture and implements various operators (separately packaged and deployable controllers) for different tasks. Source Controller is mainly responsible for pulling artifacts from external sources into the cluster, which involves authenticating those sources, detecting changes, packaging the resources and finally making them available to other controllers inside the cluster. Other controllers such as Kustomize Controller and Helm Controller run the necessary reconciliation loops to sync the state from the fetched sources by the source controller to the API server.
Now fetching external resources and syncing them to the API server is not the end of the story. Usually, depending on the content of the pulled resources, other controllers need to pick up the state that is synced by the GitOps agent and take additional actions. For instances, if the pulled configuration describes standard Kubernetes objects such as Deployments, Persistent Volumes, Secrets, etc. built-in controllers can handle the rest. But if the pulled resources are custom objects, such as the Database Server related objects that we saw in pattern 1, we need custom controllers that know how to deal with those custom objects to jump in and handle the rest. Chaining controllers to achieve such high degrees of automation by collaborating controllers is a strength of the Kubernetes Resource Model (KRM). I’ll dig a bit deeper into this aspect when I discuss combinations of reconciliation patterns further below.
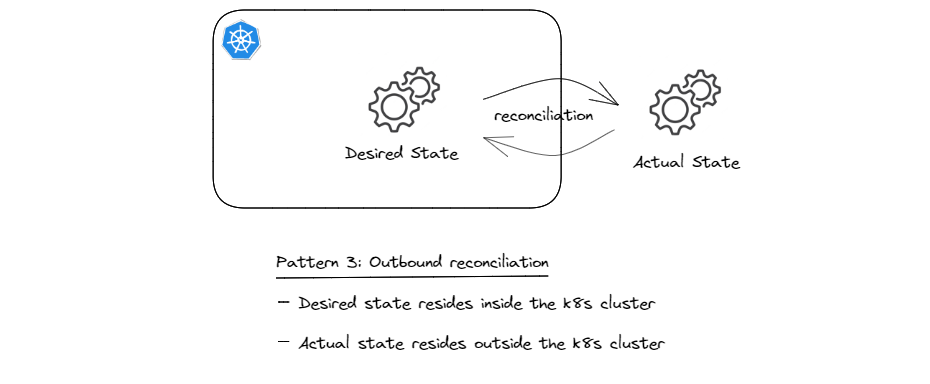
Pattern 3: Outbound Reconciliation
This pattern is similar to pattern 1 in that the desired state resides in the cluster, but the difference is that the actual state is related to an external resource and as such resides outside the cluster. The sketch below illustrates the concept.
Perhaps, the earliest prominent example of this patter is Cloud Controller Manager that allows managed Kubernetes service providers to integrate cluster APIs with their cloud APIs and managed services. One such very common integration is fulfilling Kubernetes L4 load balancer API (Service) and L7 load balancer API (Ingress) by provisioning corresponding cloud provider’s managed load balancers. Kubernetes Service and Ingress are standard API objects, but each cloud provider needs to implement their custom controllers that know how to provision and manage the lifecycle and configuration of their managed load balancers. The more evolved version of the concept of ingress, called Gateway API follows the same pattern.
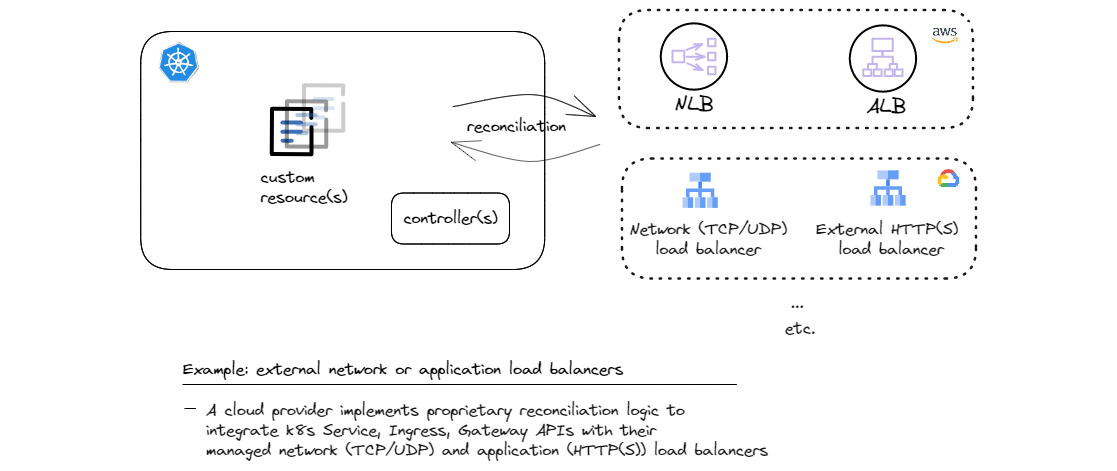
And of course this pattern can be applied to all kinds of custom API objects as well. When load balancers can be defined and provisioned from within the Kubernetes cluster, why not do the same for all other cloud provided services such as caches and databases, message buses, and a whole host of other services? I’ll outline examples of outbound reconciliation with custom resources later when discussing pattern combinations.
Patterns Are Usually Combined
The three patterns described above capture the fundamentals of different reconciliation loops and how each one contributes to the automation of part of the software-defined infrastructure stack. But as the automation of software infrastructure has gathered momentum and is covering larger parts of the stack, these patterns are often combined to achieve higher levels of automation. We’ll look at a few examples of such combinations in the this section.
Inbound + In-cluster Reconciliation
As briefly mentioned in Pattern 2, fetching artifacts from a git or an OCI repository and syncing them to the API server is only half of the story. The other half is about what happens when the API objects are synced to the API server. If these objects are standard built-in objects such as Deployments, StatefulSets, Persistent Volumes and the like, there are built-in controllers that are constantly watching for those objects and know how to reconcile the state by creating/updating the corresponding resources such as Pods (essentially containers), persistent volumes, etc4.
But for all other resources (ahem, custom resources), we still need our custom controllers to take it from there. And that was the first pattern we discussed. Schematically, we’re talking about something like this:
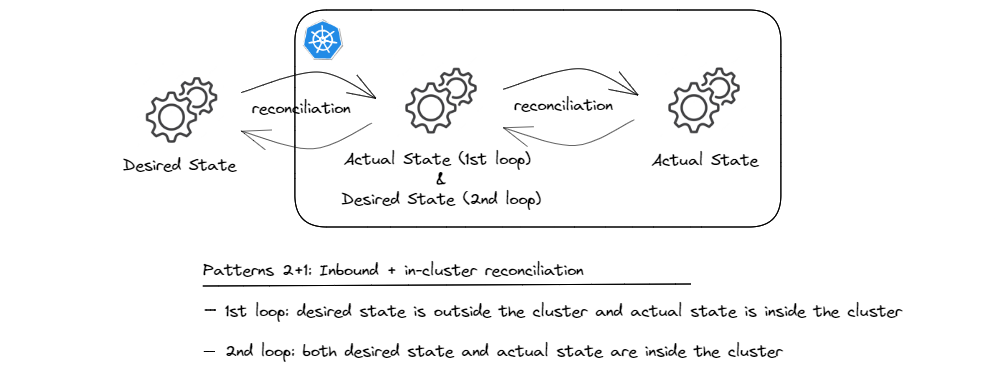
Essentially, we’re chaining custom controllers together and what’s ‘actual state’ for the first reconciliation loop becomes the ‘desired state’ for the second one. And you can imagine how such chains can be extended to cover more and more ground!
And bringing the two examples together in one sketch, we could draw something like this for the Zalando PostgreSQL operator example, but this time managed a la GitOps:
Inbound + Outbound Reconciliation
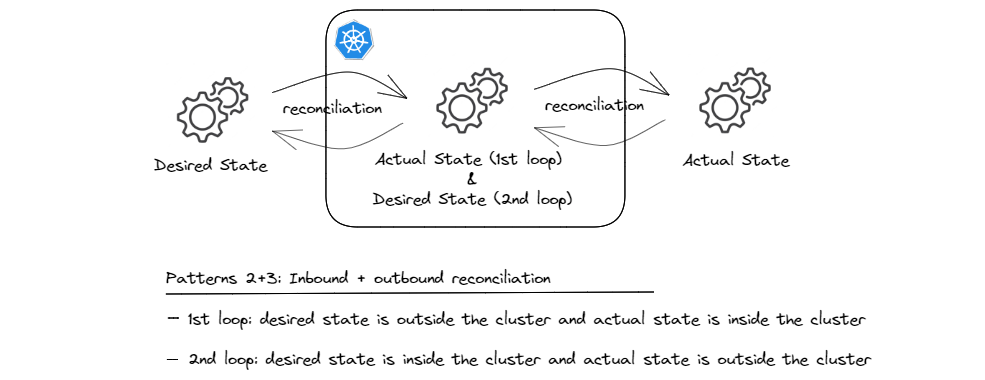
This combination has become very common in GitOps style infrastructure provisioning. The idea is that we create a modern and improved version of Infrastructure-as-Code (IaC); one that makes it possible to store the ‘intended infrastructure’ as KRM compliant manifests in a git repository and then rely on GitOps agents combined with custom controllers, typically referred to as cloud providers to collaborate with one another to provision managed services. Unlike traditional IaC, this pattern leverages the reconciliation loops that k8s controllers offer, to continuously monitor managed services’ configurations for drifts and correct them if any such drifts are detected.
And in this pattern, what is the actual state for the first loop (GitOps agents) becomes the desired state for the second loop (cloud providers).
For a concrete example of this combination, let’s reuse our GitOps agents (Flux, ArgoCD, ConfigSync, etc.) from pattern 2, but look at different examples for pattern 3. Hyperscale cloud providers offer Kubernetes add-ons (controllers) that allow managing cloud resources via Kubernetes. One of the main advantages of this approach for Kubernetes native applications is that developers can manage their entire application (both the components deployed in Kubernetes cluster as well as all the cloud managed services that the application depends on) using the same configuration model and tools, thereby reducing the cognitive load for managing the whole application. AWS Controllers for Kubernetes (ACK), Azure Service Operator, and GCP Config Connector are the solutions that the top three cloud providers offer.
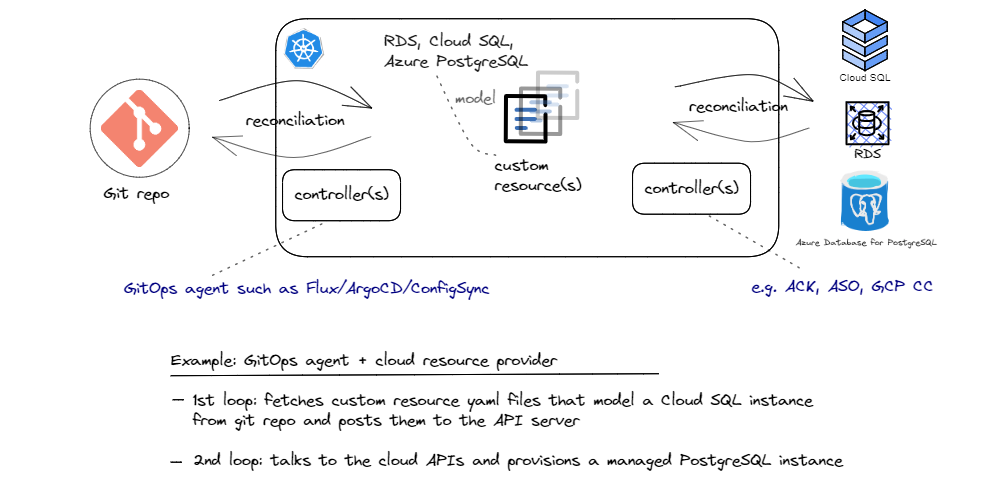
In this scenario, we store the custom objects that represent managed PostgreSQL services setting our desired configurations and policies in a git repository. Of course, the schema of such an object is cloud specific and it could look like this for Cloud SQL got PostgreSQL service in GCP and like this for RDS for PostgreSQL service in AWS. And depending on which cloud we use, we need to use a different cloud specific provider (k8s controller), as show in the sketch above. A GitOps agent then pulls the objects and syncs them to the API server. From there, the controller that is watching the API server for instances of the custom resources it owns, starts provisioing the managed PostgreSQL instance. And since these controllers are constantly running, they continue monitoring the status of the provisioned PostgreSQL instance to make sure it always fulfills the desired state specified in the custom object. In this scenario, we store the custom objects that represent managed PostgreSQL services setting our desired configurations and policies in a git repository. Of course, the schema of such an object is cloud specific and it could look like this for Cloud SQL got PostgreSQL service in GCP and like this for RDS for PostgreSQL service in AWS. And depending on which cloud we use, we need to use a different cloud specific provider (k8s controller), as show in the sketch above. A GitOps agent then pulls the objects and syncs them to the API server. From there, the controller that is watching the API server for instances of the custom resources it owns, starts provisioing the managed PostgreSQL instance. And since these controllers are constantly running, they continue monitoring the status of the provisioned PostgreSQL instance to make sure it always fulfills the desired state specified in the custom object.
Let’s bring it all together!
This post wouldn’t be complete if I didn’t show how all three patterns can be combined and illustrate a use case that shows the value of such a combination. This scenario builds on the previous pattern of provisioning managed services using GitOps tools, and adds the capability to build our own abstractions on top of the cloud APIs. Let’s assume we’d like to build our own application platform and offer a uniform definition of what a PostgreSQL server configuration should look like, regardless of which cloud provider we use. In fact, this uniform definition can even represent an on-prem PostgreSQL server that our platform team operates.
What we can do is define a new custom resource with the desired level of abstraction and implement a corresponding controller that knows how to translate our custom resource down to a a cloud specific custom resource. And of course, we would want the two resources to always be in-sync. So essentially, we add a third reconciliation loop that runs within the cluster and does the necessary work to keep the two sets of custom controllers in-sync at all times. And guess what? There is indeed a great CNCF project called Crossplane that does just that! Of course, Crossplane provides its own cloud providers instead of using ACK, GCP Config Connector, and ASO, but the architecture pattern is exactly the same. There is clearly a lot be said about Crossplane, but that’s for another post. This high level idea is shown in the sketch below.
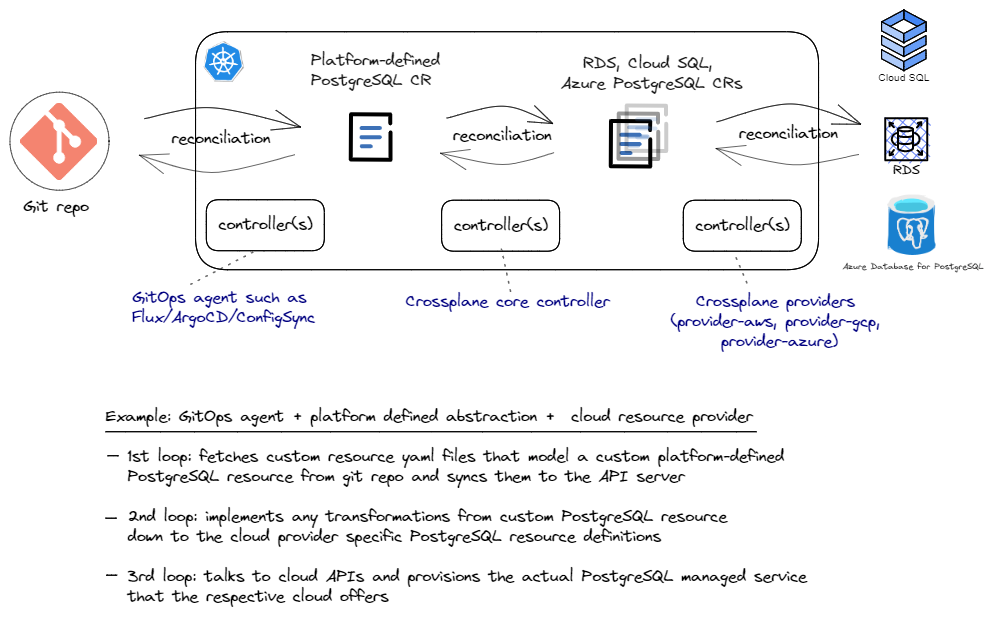
And to sum it up, it makes sense to present this combined pattern in the same abstract form as other patterns and combinations for comparison:
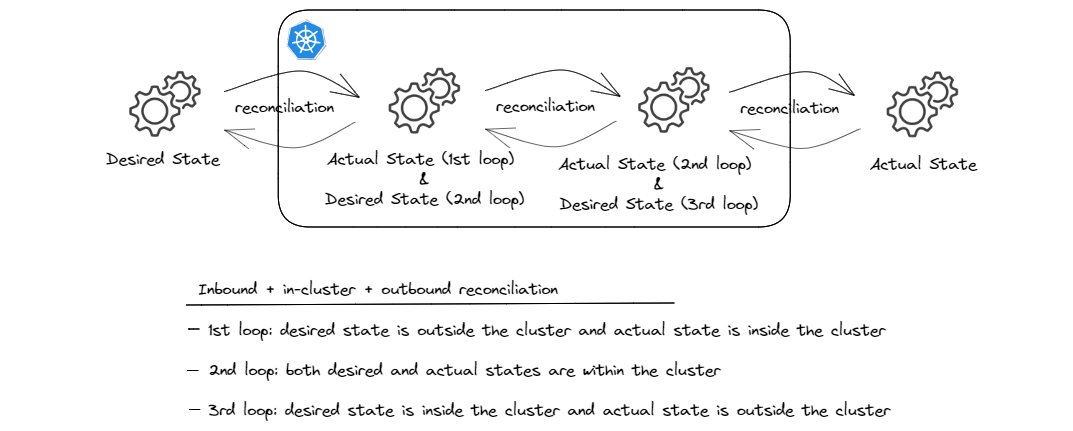
And that wraps up all the different reconciliation patterns and combinations that I wanted to cover in this post!
Summary and Closing Thoughts
This post was an attempt to explain the main enablers for Kubernetes to evolve from ‘just a container orchestration engine’ to a powerful automation platform that has sparked a lot of innovation over the past few years. It also provided an abstract view of various reconciliation/automation patterns along with several concrete examples to better illustrate the points. I believe we’ll see even more innovation in this space, and hopefully the next time you see a Kubernetes related project that automates some aspect of software infrastructure, you’ll be able to recognize the pattern they adopt and more easily understand the architecture and scope of the project.
If you have any thoughts,or questions related this post or suggestions for future posts, please feel free to send me a message @hkassaei on Twitter or Hossein Kassaei on LinkedIn. I’d love to hear from you!
-
This Podcast is also a great listen if you’d like to hear more about the kinds of problems the Kubernetes community was facing in those early years and how CRDs and Custom Controllers tremendously helped scale the open source collaboration and innovation by enabling a lot of ‘out of tree’ development as opposed to the default in-tree development style. ↩︎
-
You can even model physical objects; e.g. things around the house, sensors, cars, trucks, etc. as Kubernetes custom resources and practically build digital twins for them. In fact, this talk presents this very same idea! ↩︎
-
A valid question could be “but where was the data before being posted to the API server and shouldn’t that original place be considered the single source of truth?” This aspect will be addressed as part of Pattern 2 in more detail, but sometimes the data may be posted to the API server imperatively, e.g. using kubectl. ↩︎
-
Of course, there’s a lot happening under the hood in terms of interactions between various Kubernetes components such as the API server, scheduler, controller-manager, kubelet, and finally down to the container runtime, but since this post is meant to focus on reconciliation loops, I try not to digress. You can for sure find a great overview of Kubernetes architecture and components here ↩︎